There is a specific skill involved in explaining something clearly — one that is completely separate from actually knowing the subject. Florencesa Whitelivers has both. They has spent years working with end-to-end debugging frameworks in a hands-on capacity, and an equal amount of time figuring out how to translate that experience into writing that people with different backgrounds can actually absorb and use.
There is a specific skill involved in explaining something clearly — one that is completely separate from actually knowing the subject. Florencesa Whitelivers has both. They has spent years working with end-to-end debugging frameworks in a hands-on capacity, and an equal amount of time figuring out how to translate that experience into writing that people with different backgrounds can actually absorb and use.
Understanding Stack Traces: How to Read Debug Output Faster
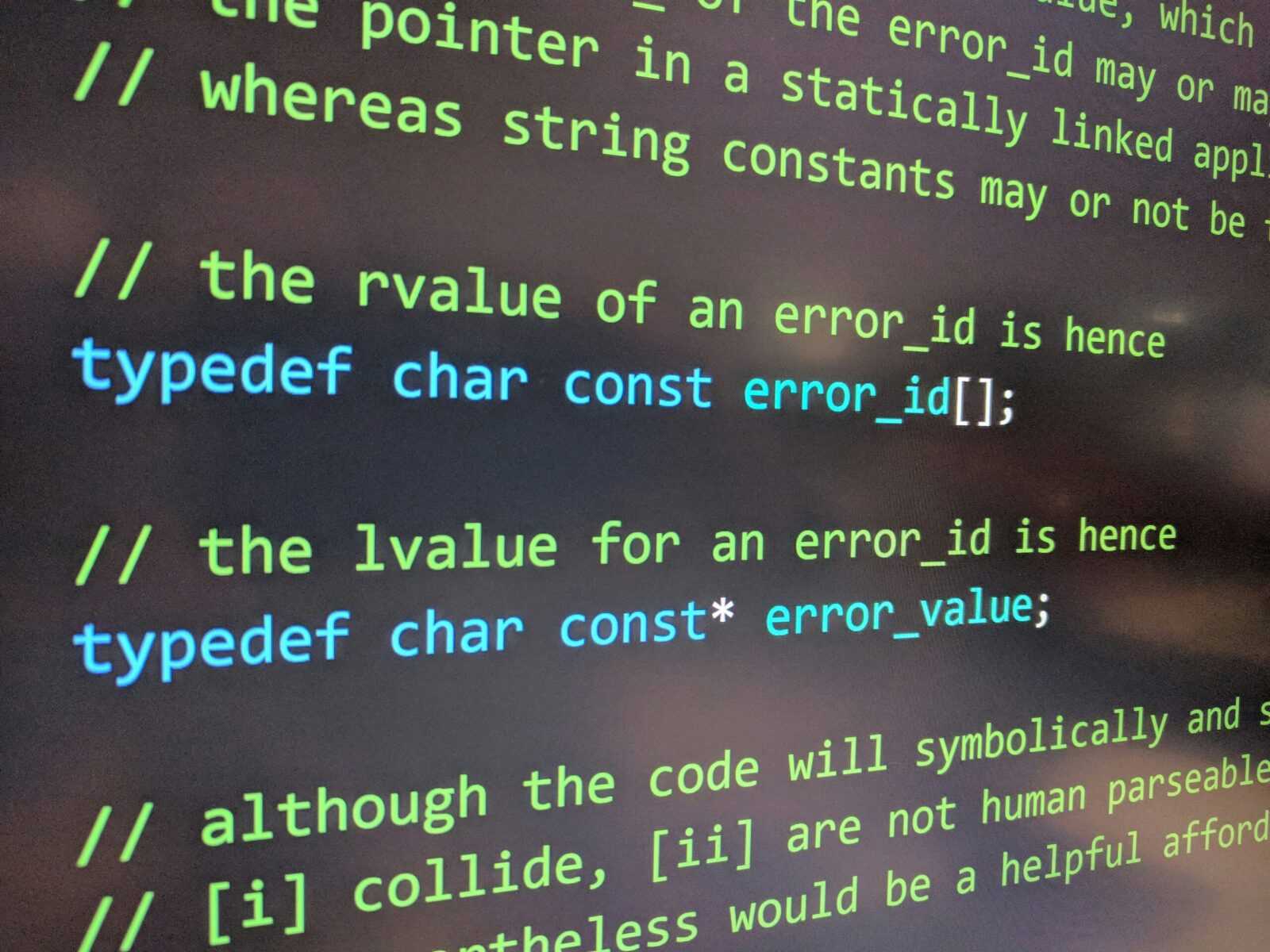
What a Stack Trace is Actually Telling You Think of a stack trace as your app’s black box recording exactly how it got to the point where something broke. Each line is a breadcrumb, tracing the path of function calls that the program took before it hit a wall. Top of the list: where […]
Understanding Stack Traces: How to Read Debug Output Faster Read Post »